
Deep Learning vs Big Data: Who owns what? - Selamat datang di situs media global terbaru Xivanki, Pada halaman ini kami menyajikan informasi tentang Deep Learning vs Big Data: Who owns what? !! Semoga tulisan dengan kategori
backpropagation !!
berkeley !!
big data !!
caffe !!
clarifai !!
compiled !!
copyright !!
CVPR 2015 !!
data science !!
deep learning !!
derivative work !!
google !!
gpu !!
imagenet !!
legal !!
metamind !!
nearest neighbor !!
snapchat !!
stanford !!
vision.ai !! ini bermanfaat bagi anda. Silahkan sebarluaskan postingan Deep Learning vs Big Data: Who owns what? ini ke social media anda, Semoga rezeki berlimpah ikut dimudahkan Allah bagi anda, Lebih jelas infonya lansung dibawah -->
In order to learn anything useful, large-scale multi-layer deep neural networks (aka Deep Learning systems) require a large amount of labeled data. There is clearly a need for big data, but only a few places where big visual data is available. Today we'll take a look at one of the most popular sources of big visual data, peek inside a trained neural network, and ask ourselves some data/model ownership questions. The fundamental question to keep in mind is the following, "Are the learned weights of a neural network derivate works of the input images?" In other words, when deep learning touches your data, who owns what?
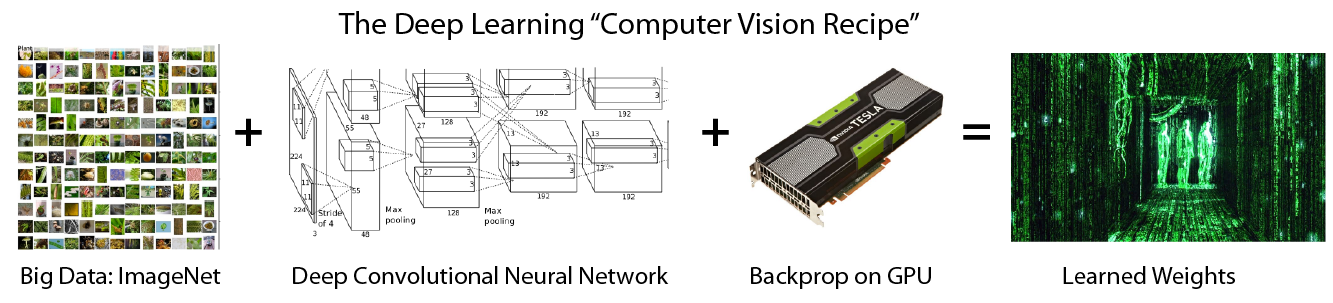
Background: The Deep Learning "Computer Vision Recipe"
One of today's most successful machine learning techniques is called Deep Learning. The broad interest in Deep Learning is backed by some remarkable results on real-world data interpretation tasks dealing with speech[1], text[2], and images[3]. Deep learning and object recognition techniques have been pioneered by academia (University of Toronto, NYU, Stanford, Berkeley, MIT, CMU, etc), picked up by industry (Google, Facebook, Snapchat, etc), and are now fueling a new generation of startups ready to bring visual intelligence to the masses (Clarifai.com, Metamind.io, Vision.ai, etc). And while it's still not clear where Artificial Intelligence is going, Deep Learning will be a key player.
Related blog post: Deep Learning vs Machine Learning vs Pattern Recognition
Related blog post: Deep Learning vs Probabilistic Graphical Models vs Logic
For visual object recognition tasks, the most popular models are Convolutional Neural Networks (also known as ConvNets or CNNs). They can be trained end-to-end without manual feature engineering, but this requires a large set of training images (sometimes called big data, or big visual data). These large neural networks start out as a Tabula Rasa (or "blank slate") and the full system is trained in an end-to-end fashion using a heavily optimized implementation of Backpropagation (informally called "backprop"). Backprop is nothing but the chain rule you learned in Calculus 101 and today's deep neural networks are trained in almost the same way they were trained in the 1980s. But today's highly-optimized implementations of backprop are GPU-based and can process orders of magnitude more data than was approachable in the pre-internet pre-cloud pre-GPU golden years of Neural Networks. The output of the deep learning training procedure is a set of learned weights for the different layers defined in the model architecture -- millions of floating point numbers representing what was learned from the images. So what's so interesting about the weights? It's the relationship between the weights and the original big data, that will be under scrutiny today.
"Are weights of a trained network based on ImageNet a derived work, a cesspool of millions of copyright claims? What about networks trained to approximate another ImageNet network?"
[This question was asked on HackerNews by kastnerkyle in the comments of A Revolutionary Technique That Changed Machine Vision.]
In the context of computer vision, this question truly piqued my interest, and as we start seeing robots and AI-powered devices enter our homes I expect much more serious versions of this question to arise in the upcoming decade. Let's see how some of these questions are being addressed in 2015.
1. ImageNet: Non-commercial Big Visual Data
Let's first take a look at the most common data source for Deep Learning systems designed to recognize a large number of different objects, namely ImageNet[4]. ImageNet is the de-facto source of big visual data for computer vision researchers working on large scale object recognition and detection. The dataset debuted in a 2009 CVPR paper by Fei-Fei Li's research group and was put in place to replace both PASCAL datasets (which lacked size and variety) and LabelMe datasets (which lacked standardization). ImageNet grew out of Caltech101 (a 2004 dataset focusing on image categorization, also pioneered by Fei-Fei Li) so personally I still think of ImageNet as something like "Stanford10^N". ImageNet has been a key player in organizing the scale of data that was required to push object recognition to its new frontier, the deep learning phase.

ImageNet has over 15 million images in its database as of May 1st, 2015.
Problem: Lots of extremely large datasets are mined from internet images, but these images often come with their own copyright. This prevents collecting and selling such images, and from a commercial point of view, when creating such a dataset, some care has to be taken. For research to keep pushing the state-of-the-art on real-world recognition problems, we have to use standard big datasets (representative of what is found in the
"ImageNet does not own the copyright of the images. ImageNet only provides thumbnails and URLs of images, in a way similar to what image search engines do. In other words, ImageNet compiles an accurate list of web images for each synset of WordNet. For researchers and educators who wish to use the images for non-commercial research and/or educational purposes, we can provide access through our site under certain conditions and terms."
2. Caffe: Unrestricted Use Deep Learning Models
Now that we have a good idea where to download big visual data and an understanding of the terms that apply, let's take a look at the the other end of the spectrum: the output of the Deep Learning training procedure. We'll take a look at Caffe, one of the most popular Deep Learning libraries, which was engineered to handle ImageNet-like data. Caffe provides an ecosystem for sharing models (the Model Zoo), and is becoming an indispensable tool for today's computer vision researcher. Caffe is developed at the Berkeley Vision and Learning Center (BVLC) and by community contributors -- it is open source.

Slide from DIY Deep Learning for Vision with Caffe
Problem: As a project that started at a University, Caffe's goal is to be the de-facto standard for creating, training, and sharing Deep Learning models. The shared models were initially licensed for non-commercial use, but the problem is that a new wave of startups is using these techniques, so there must be a licensing agreement which allows Universities, large companies, and startups to explore the same set of pretrained models.
Solution: The current model licensing for Caffe is unrestricted use. This is really great for a broad range of hackers, scientists, and engineers. The models used to be shared with a non-commercial clause. Below is the entire model licensing agreement from the Model License section of Caffe (taken on May 5th, 2015).
"The Caffe models bundled by the BVLC are released for unrestricted use.
These models are trained on data from the ImageNet project and training data includes internet photos that may be subject to copyright.
Our present understanding as researchers is that there is no restriction placed on the open release of these learned model weights, since none of the original images are distributed in whole or in part. To the extent that the interpretation arises that weights are derivative works of the original copyright holder and they assert such a copyright, UC Berkeley makes no representations as to what use is allowed other than to consider our present release in the spirit of fair use in the academic mission of the university to disseminate knowledge and tools as broadly as possible without restriction."
3. Vision.ai: Dataset generation and training in your home
Deep Learning learns a summary of the input data, but what happens if a different kind of model memorizes bits and pieces of the training data? And more importantly what if there are things inside the memorized bits which you might not want shared with outsiders? For this case study, we'll look at Vision.ai, and their real-time computer vision server which is designed to simultaneously create a dataset and learn about an object's appearance. Vision.ai software can be applied to real-time training from videos as well as live webcam streams.
Instead of starting with big visual data collected from internet images (like ImageNet), the vision.ai training procedure is based on a person waving an object of interest in front of the webcam. The user bootstraps the learning procedure with an initial bounding box, and the algorithm continues learning hands-free. As the algorithm learns, it is stores a partial history of what it previously saw, effectively creating its own dataset on the fly. Because the vision.ai convolutional neural networks are designed for detection (where an object only occupies a small portion of the image), there is a large amount of background data presented inside the collected dataset. At the end of the training procedure you get both the Caffe-esque bit (the learned weights) and the ImageNet bit (the collected images). So what happens when it's time to share the model?

A user training a cup detector using vision.ai's real-time detector training interface
Problem: Training in your home means that potentially private and sensitive information is contained inside the backgrounds of the collected images. If you train in your home and make the resulting object model public, think twice about what you're sharing. Sharing can also be problematic if you have trained an object detector from a copyrighted video/images and want to share/sell the resulting model.
Solution: When you save a vision.ai model to disk, you get both a compiled model and the full model. The compiled model is the full model sans the images (thus much smaller). This allows you to maintain fully editable models on your local computer, and share the compiled model (essentially only the learned weights), without the chance of anybody else peeking into your living room. Vision.ai's computer vision server called VMX can run both compiled and uncompiled models; however, only uncompiled models can be edited and extended. In addition, vision.ai provides their vision server as a standalone install, so that all of the training images and computations can reside on your local computer. In brief, vision.ai's solution is to allow you to choose whether you want to run the computations in the cloud or locally, and whether you want to distribute full models (with background images) or the compiled models (solely what is required for detection). When it comes to sharing the trained models and/or created datasets, you are free to choose your own licensing agreement.
4. Open Problems for Licensing Memory-based Machine Learning Models
Deep Learning methods aren't the only techniques applicable to object recognition. What if our model was a Nearest-Neighbor classifier using raw RGB pixels? A Nearest Neighbor Classifier is a memory based classifier which memorizes all of the training data -- the model is the training data. It would be contradictory to license the same set of data differently if one day it was viewed as training data and another day as the output of a learning algorithm. I wonder if there is a way to reconcile the kind of restrictive non-commercial licensing behind ImageNet with the unrestricted licensing use strategy of Caffe Deep Learning Models. Is it possible to have one hacker-friendly data/model license agreement to rule them all?
Conclusion
Don't be surprised if neural network upgrades come as part of your future operating system. As we transition from a data economy (sharing images) to a knowledge economy (sharing neural networks), legal/ownership issues will pop up. I hope that the three scenarios I covered today (big visual data, sharing deep learning models, and training in your home) will help you think about the future legal issues that might come up when sharing visual knowledge. When AI starts generating its own art (maybe by re-synthesizing old pictures), legal issues will pop up. And when your competitor starts selling your models and/or data, legal issues will resurface. Don't be surprised if the MIT license vs. GPL license vs. Apache License debate resurges in the context of pre-trained deep learning models. Who knows, maybe AI Law will become the next big thing.
References
[1] Deep Speech: Accurate Speech Recognition with GPU-Accelerated Deep Learning: NVIDIA dev blog post about Baidu's work on speech recognition using Deep Learning. Andrew Ng is working with Baidu on Deep Learning.
[2] Text Understanding from Scratch: Arxiv paper from Facebook about end-to-end training of text understanding systems using ConvNets. Yann Lecun is working with Facebook on Deep Learning.
[3] ImageNet Classification with Deep Convolutional Neural Networks. Seminal 2012 paper from the Neural Information and Processing Systems (NIPS) conference which showed breakthrough performance from a deep neural network. Paper came out of University of Toronto, but now most of these guys are now at Google. Geoff Hinton is working with Google on Deep Learning.
[4] J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li and L. Fei-Fei, ImageNet: A Large-Scale Hierarchical Image Database. IEEE Computer Vision and Pattern Recognition (CVPR), 2009.
Jia Deng is now assistant professor at Michigan University and he is growing his research group. If you're interested in starting a PhD in deep learning and vision, check out his call for prospective students. This might be a younger version of Andrew Ng.
Richard Socher is the CTO and Co-Founder of MetaMind, and new startup in the Deep Learning space. They are VC-backed and have plenty of room to grow.
Jia Li is now Head of Research at Snapchat, Inc. I can't say much, but take a look at the recent VentureBeat article: Snapchat is quietly building a research team to do deep learning on images, videos. Jia and I overlapped at Google Research back in 2008.
Fei-Fei Li is currently the Director of the Stanford Artificial Intelligence Lab and the Stanford Vision Lab. See the article on Wired: If we want our machines to think, we need to teach them to see. Yann, you have some competition.
Yangqing Jia created the Caffe project during his PhD at UC Berkeley. He is now a research scientist at Google.
Tomasz Malisiewicz is the Co-Founder of Vision.ai, which focuses on real-time training of vision systems -- something which is missing in today's Deep Learning systems. Come say hi at CVPR.
Demikian info Deep Learning vs Big Data: Who owns what?, Semoga dengan adanya postingan ini, Anda sudah benar benar menemukan informasi yang memang sedang anda butuhkan saat ini. Bagikan informasi Deep Learning vs Big Data: Who owns what? ini untuk orang orang terdekat anda, Bagikan infonya melalui fasilitas layanan Share Facebook maupun Twitter yang tersedia di situs ini.